
What We Do in the UXO Show Case
Large amounts of unexploded ordnances were dumped in the oceans after the second world war. We developed a workflow to detect objects on the seafloor using a variety of sensors to identify possible targets and validate them. At the center of our workflow are artificial intelligence methods to automate large parts of the workflow.
We developed a workflow to detect and classify unexploded ordnance (UXO) at the seafloor. The workflow uses a wide range of data types. Multibeam echosounders (MBES) are used to create detailed bathymetric maps and sub bottom profilers (SBP) are used to analyze the composition of the seafloor. This method allows us to cover large areas. Autonomous underwater vehicles (AUVs) are equipped with cameras and magnetometers to get detailed data for small areas of the seafloor. The first step in our workflow is the manual annotation workflow of MBES and SBP data. This data is used in the machine learning model training workflow to train models in a supervised fashion for detection and classification. Additionally, we can use unsupervised methods to distinguish UXO types using clustering methods. The manual validation and active learning workflow is used to evaluate and improve the machine learning models. Finally, we evaluate the machine learning models using detailed data from the AUVs in the data-based validation workflow. A combination of these methods is used to annotate the input data (in SBP data the task is usually easier, and the data can be annotated directly). The annotation can include a classification into different UXO types or non-UXO objects. For supervised models we use the manual annotations to create models for both detection and classification of UXO objects. Numerous methods exist to approach this task. We usually rely on neural network-based methods due to their flexibility and performance in various tasks. Common data augmentation methods are used to increase the robustness of the models and train-validation splits are used to prevent overfitting. The biggest challenge is the relatively low resolution of the input data. Unsupervised learning methods are used to classify annotated objects into different groups. Here we rely on information generated in the manual annotation workflow and common data clustering methods like K-Means clustering. An important element of both parts is the documentation of the data preparation. This is crucial when new datasets are used in combination with trained models to create predictions. Incomplete or inaccurate modifications can lead to worse model performances. Alternatively, the training step can be skipped, and the focus can be set on the evaluation of the model predictions. Different models are compared, and possible issues are identified. To be able to use these data sets two steps are necessary. The first step is the annotation of objects or anomalies in the data sets. This can be done either manually or using adequate machine learning models (e.g. a neural network trained on images of UXO objects on underwater images). The annotations are then used to align the data sets. This step is crucial for the analysis and necessary as AUVs are not able to locate themselves precisely underwater. Finally, annotations and predictions are compared to evaluate the model performance.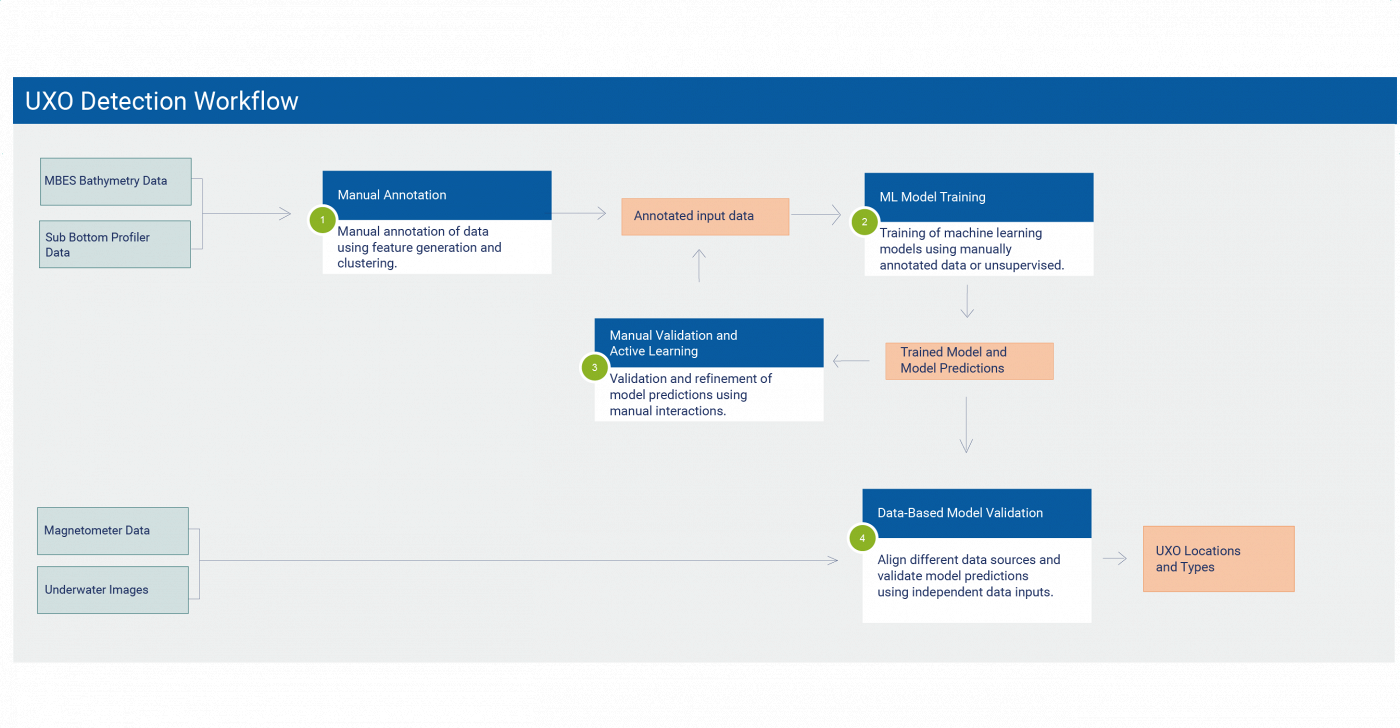
Manual Annotation Workflow
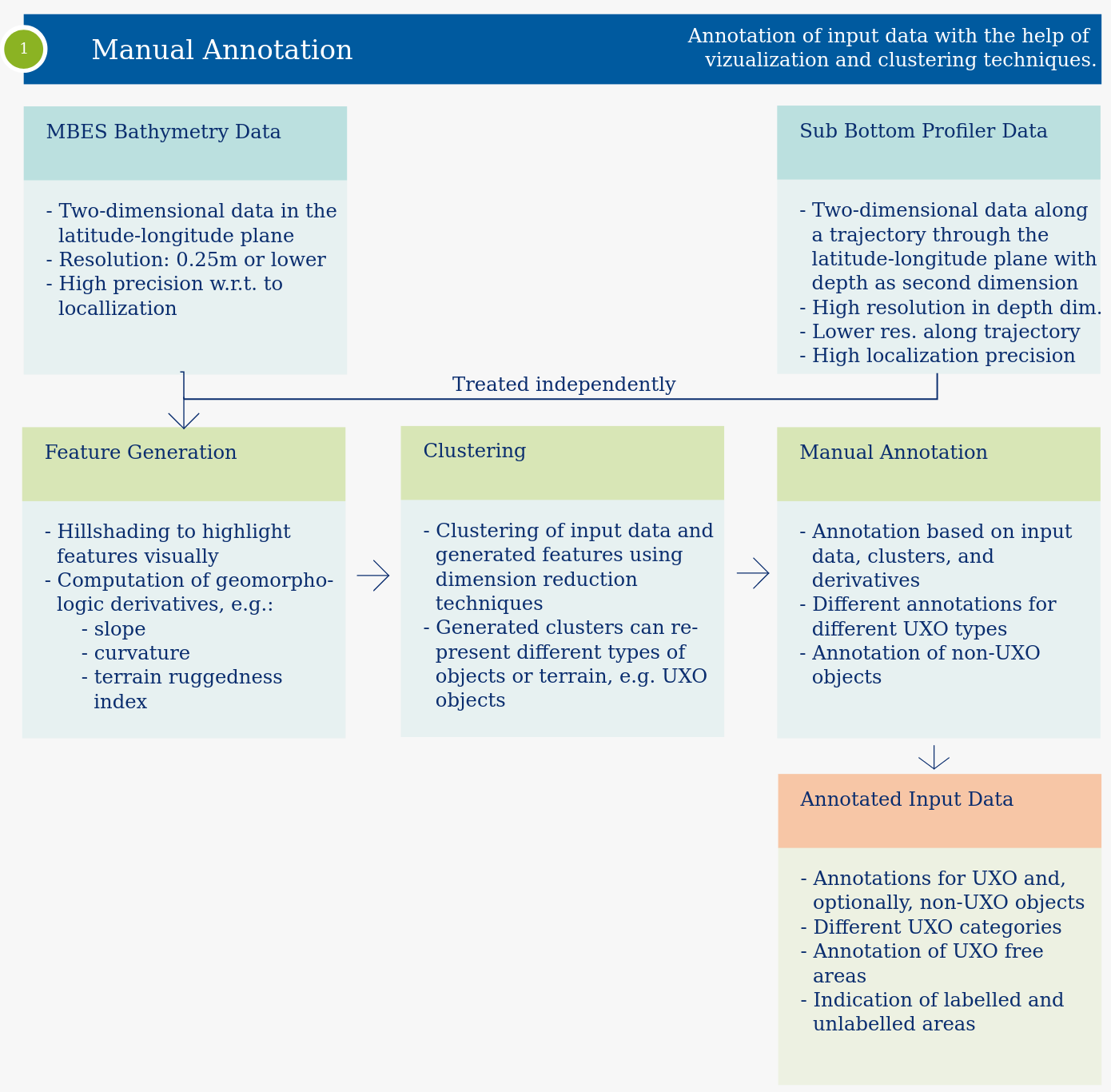 The manual annotation workflow is used to generate manual annotations for MBES and SBD data sets. Especially for MBES data, the individual UXO objects are hard to see directly in the bathymetry. It is therefore necessary to support the human eye with improved visualizations of the data. This can be done in multiple ways. On simple option is to use hill shading to highlight objects on the seafloor. Additionally, it is possible to generate features which enable a better highlighting of UXO objects. These features are generated using geomorphological methods like the slope or the curvature. Further processing of the data using clustering methods can lead to a classification of the seafloor where UXO objects as a unique class.
The manual annotation workflow is used to generate manual annotations for MBES and SBD data sets. Especially for MBES data, the individual UXO objects are hard to see directly in the bathymetry. It is therefore necessary to support the human eye with improved visualizations of the data. This can be done in multiple ways. On simple option is to use hill shading to highlight objects on the seafloor. Additionally, it is possible to generate features which enable a better highlighting of UXO objects. These features are generated using geomorphological methods like the slope or the curvature. Further processing of the data using clustering methods can lead to a classification of the seafloor where UXO objects as a unique class.ML Model Training Workflow
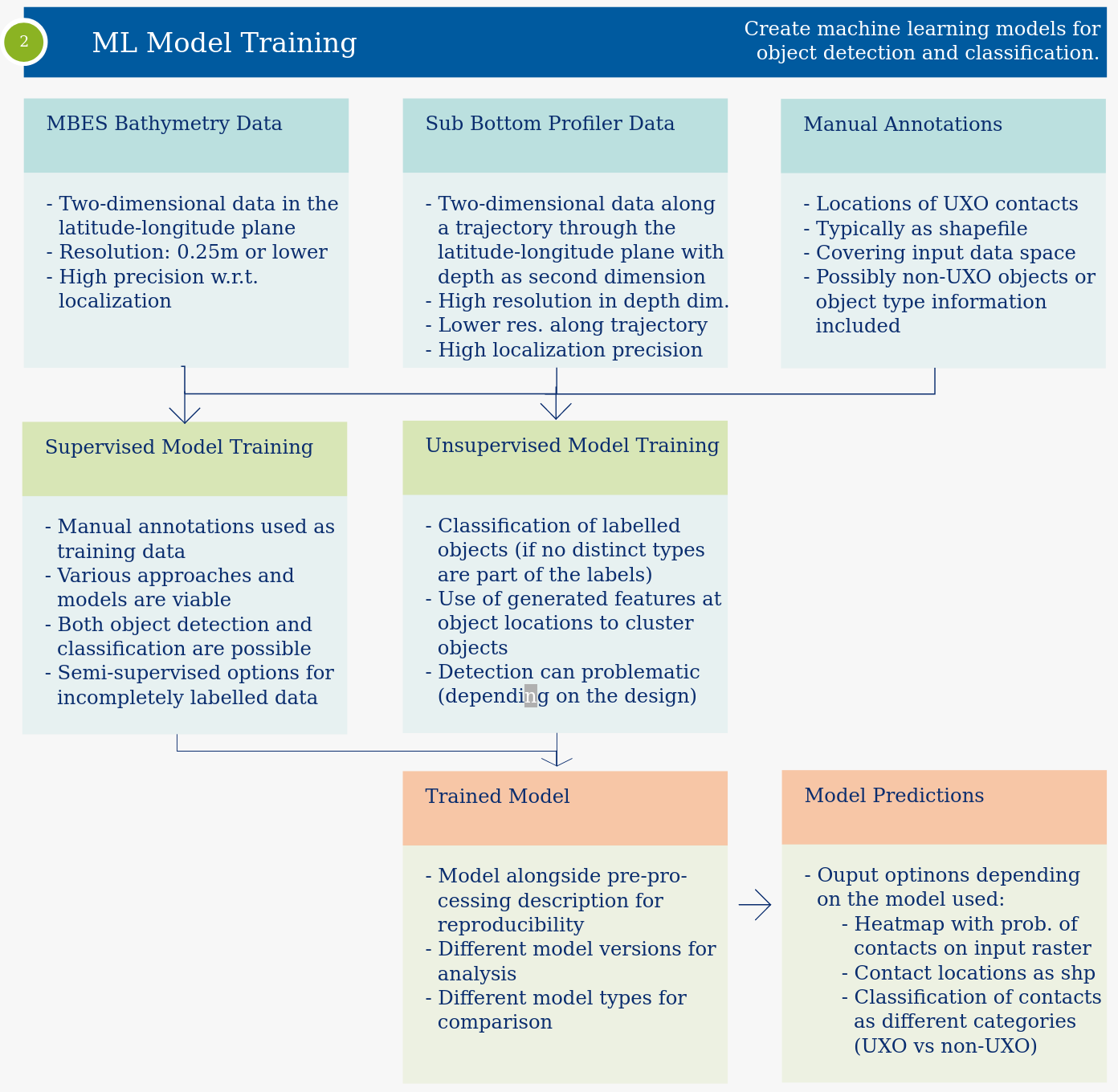 The machine learning model training workflow can be split into two parts, a supervised and an unsupervised part.
The machine learning model training workflow can be split into two parts, a supervised and an unsupervised part.Manual Validation and Active Learning Workflow
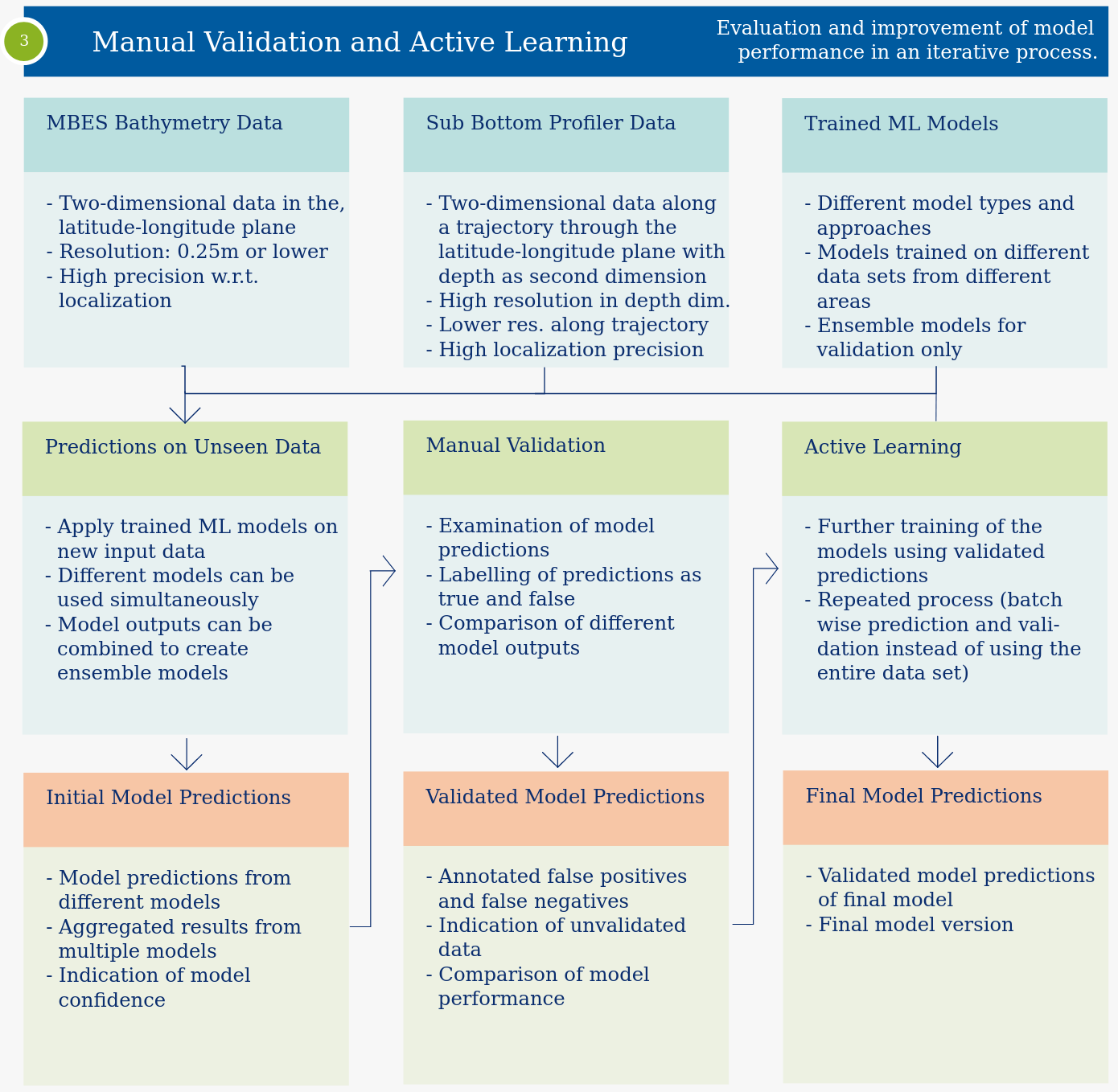 The manual validation and active learning workflow is used to improve and evaluate the model performance of different models. Using different data sets we can create different machine learning models. These models may not generalize well to new data sets. Therefore, the manual validation of their predictions is necessary. Using the corrected predictions as input data for additional training, the model performance on new data can be improved.
The manual validation and active learning workflow is used to improve and evaluate the model performance of different models. Using different data sets we can create different machine learning models. These models may not generalize well to new data sets. Therefore, the manual validation of their predictions is necessary. Using the corrected predictions as input data for additional training, the model performance on new data can be improved.Data-Based Validation Workflow
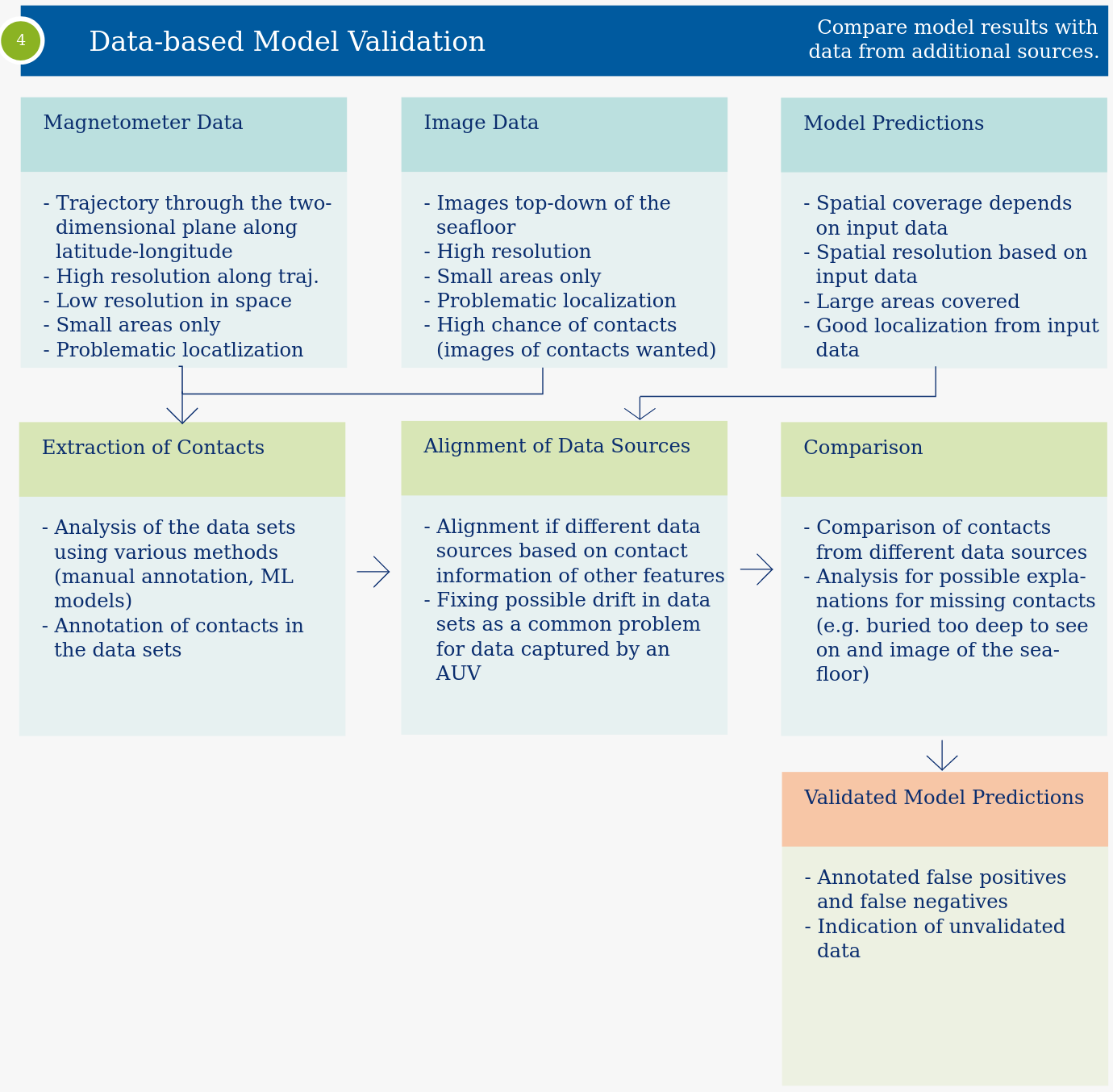 An alternative way to validate the predictions of machine learning models is to use auxiliary data sets generated using AUVs. These provide additional information on objects on the seafloor. The two common types of data are underwater images and magnetometer data. On underwater images objects on the seafloor can be seen and identified. Magnetometer data can give hints to metallic objects not just on the seafloor but also beneath. It is therefore especially important for SBP data validation, as the other data sources do not allow these insights. It is worth mentioning, that these methods only cover small areas compared MBES and SBP mapping.
An alternative way to validate the predictions of machine learning models is to use auxiliary data sets generated using AUVs. These provide additional information on objects on the seafloor. The two common types of data are underwater images and magnetometer data. On underwater images objects on the seafloor can be seen and identified. Magnetometer data can give hints to metallic objects not just on the seafloor but also beneath. It is therefore especially important for SBP data validation, as the other data sources do not allow these insights. It is worth mentioning, that these methods only cover small areas compared MBES and SBP mapping.